If this is the age of information, which it is, then surely we can reasonably suggest that all businesses need to get more closely acquainted with the data streams traversing their operational models. Getting better acquainted with information in real terms means understanding data at a more granular level. But don’t panic, this does not require a degree in computer science or a PhD in systems analytics.
Business managers, salespeople and every company stakeholder through to administration staff can and should now develop a rudimentary working understanding of what size, shape and flavour their firm’s data exists in. We all need to travel this learning curve because cloud computing services enjoy increasingly widespread acceptance across all transepts of business.
As cloud data is processed, analysed and ultimately stored back in the cloud datacentre, it has become a more fundamental and integral part of business. Technology analysts suggest that firms in all verticals will soon start to qualify and quantify the data they hold as an item on the balance sheet. Knowing what type of data you own has suddenly become very important.
As we start to understand the difference between distinct chunks of data, we can begin to understand how to treat each piece or chunk of cloud differently. This has huge implications for how we approach the security, privacy and identity management of every piece of cloud data we create.
The challenge we are faced with is one of serving the right data dish to the right table at the right time
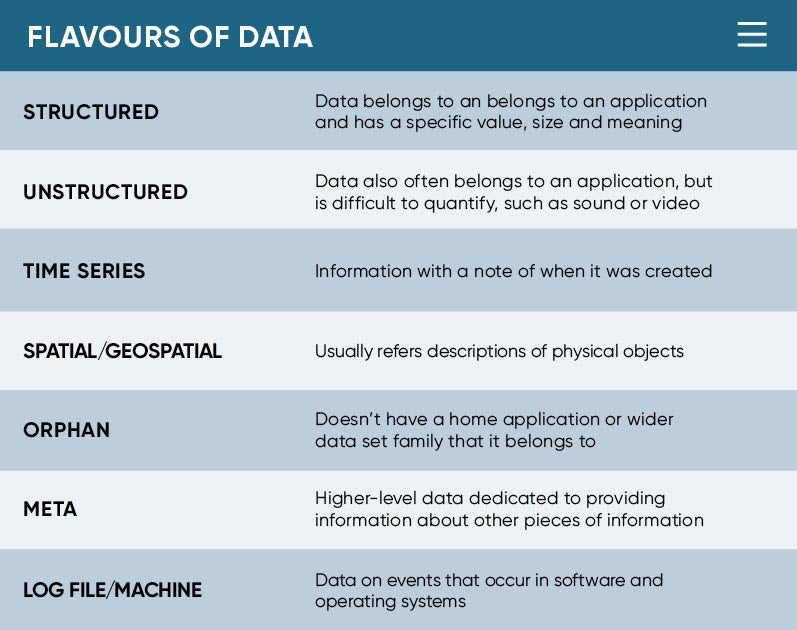
As a starter menu guide, structured data belongs to an application and has a specific value, size and meaning. Unstructured or semi-structured data also often belongs to an application, but it could take the form of sound, video or some other more difficult to quantify and quality block of information.
Deeper down we find time series data, which in simple terms is just information with a note of when it was created. Spatial or geospatial data usually refers to descriptions of physical objects. Orphan data, you guessed it, doesn’t have a home application or wider data set family that it belongs to. Then there’s meta data, which is higher level data dedicated to providing information about other pieces of information.
Deeper still, we find log file and machine data. This is data from the information channels that computers generate so they can record every single click and function in their universe, and they also often use it to talk to other machines. The widely discussed big data has a recipe book all of its own, but put simply it describes any scenario when the water spout is flowing faster than any normal person could drink from. So you see, there is a veritable smörgåsbord to be had out there.
“It’s worth remembering that there are many different kinds, or indeed flavours, of cloud data and they need to be treated differently. Data that’s used for monitoring might be appropriate for a time-series database. But even big data isn’t a singular thing. Data may be big in volume, which brings its own sets of challenges to store it and, especially, to move it. But data may also be big in terms of how quickly it needs to be processed and so it requires the data to be close to the applications using it,” says Gordon Haff, cloud evangelist for open source platform company Red Hat.
Will Ochandarena, director of product management at cloud database company MapR, favours the concept of cloud data flavours, but he says that wider business knowledge of the recipe being concocted here has implications. He says organisations that try to take a one-size-fits-all approach to data management will spoil the broth. This is because different flavours of data need to be managed by different service level agreements or they require different seasoning and cooking times, if you care to extend the flavoursome foodie analogy.
“The challenge we are faced with is one of serving the right data dish to the right table at the right time,” says Sumit Sarkar, chief data evangelist at business applications company Progress. But his enthusiasm also comes with a warning because we are compartmentalising certain elements of cloud computing into what are called microservices and containers.
Containers condense discrete and defined components of application logic into a smaller space. Equally, microservices encapsulate an individual application action, such as making an online payment, into a pre-engineered smaller space. Both of these highly popularised cloud practices almost represent preprepared ready meals where the ingredients and recipe are not necessarily revealed. Mr Sarkar explains that this means that it will be tougher to get close to the organic source of data itself.
“These factors make it challenging for business analysts, data engineers and data scientists to get access to the right level of data for more of a self-service strategy. It’s very difficult to predict the best use of data until you get it into the hands of your analytical teams. Or indeed make it upwardly available to the new breed of business users with an interest in data,” he says.
Cloud data is a dish best served hot or cold or warm and it can come on a silver platter or an automated sushi-style conveyor belt, just so long as it’s fit for consumption. But cloud data starts to lose its flavour when it comes as a ready meal or as secret sauce. The table is set for more cloud data, but we want it organic and we want to know its provenance. Dinner is now served “as a service”.


