Artificial intelligence: it’s the “magic” that can solve every business problem imaginable. Except when it can’t. Often, even where AI systems could provide revolutionary solutions, there are practical limitations. If your AI is going to learn from data, how do you make sure it has the right amount of data and that it’s data you can use without heading straight for a legal minefield? This is where data synthesis comes in.
One reason companies are increasingly turning to data synthesis methods to build AI systems is primarily because synthetic data is easier to create. Take the example of software to direct self-driving cars. If building a learning model from real data, you would need to drive an actual car for millions of miles and even then you might not, and might not want to, encounter every situation a car could need to deal with. For example, you wouldn’t want to test a real car’s response to having a real toddler run out in front of it.
One solution to work around this is to train networks using simulated data by running a machine-learning algorithm on images of a virtual car driving through virtual environments, as in a video game. Grand Theft Auto, for example, was found to be a surprisingly effective tool for simulation in a study run by Intel and a German university in 2017. You can rapidly build a data set of massively varied situations that a real car might encounter without having to stage them in real time.
Big data without big cost
Using data synthesis methods to expand your corpus of data rapidly can also be useful for startups trying to compete with more established rivals. For obvious reasons, a small, new company has had less opportunity to gather real data to train algorithms. And realistic synthetic data gives them an opportunity to catch up, along with a better shot at disrupting the market. 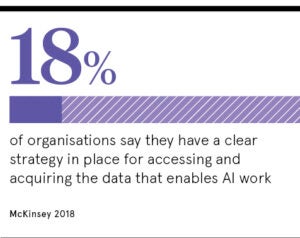
Synthetic data can be used where there may be privacy concerns with real data, in healthcare or finance, for instance. Researchers have used machine-learning to generate x-rays showing different medical conditions which in turn have been used to train learning models. Because the data is synthetic, they can create far larger training sets that can be used without concern for patient privacy. Along similar lines, fraud detection systems can be trained using data synthesis methods without having to worry about exposing real financial data.
But synthetic data is of very limited use when you’re trying to learn something new about the real world as the results will only ever tell you about the model of the world that generated the data. Reality can often turn out to be a lot more complex than even the cleverest predictive analytics have accounted for.
And even when testing established principles, synthetic data should always be used carefully. Has your clever neural network unintentionally eliminated edge cases that you should be testing against because they’re too statistically rare to show in the model, for example? Have you unintentionally propagated bias in the real data into the synthetic data?
While data synthesis methods can help build AI systems more quickly and cost effectively, it’s important to understand the limitations and risks. Ultimately, you’re never going to be able to innovate without the real stuff.
Big data without big cost




