
The challenge lies with the near infinite number of file types and variations within each type in which data can live. Every program and application you use creates different file types: email, chat, social media, planning, content-creation tools and so on. Different versions of the same program or application create variations of those file types and different formatting within each of these can create still more variations.
Here are four data challenges to discuss with your organization’s IT director, so you can begin a data inventory and put policies in place ahead of litigation, which will greatly reduce potential roadblocks.
Fringes: legacy and bleeding edge
Have you ever cleaned out your cupboard and found that shoebox full of cassettes from schooldays? Businesses are no different. Many of their electronic files are stored as legacy file types which are no longer supported. A good example is a company that needed to review files which were saved on eight-inch floppy disks. Knowing this ahead of litigation is important.
At the other end of that spectrum, being on the forefront of technology is great, but when it comes to preparing files for e-discovery, it can slow things down. Like knowing about legacy files, it’s also important to take note of recently developed software or applications your organization may use which creates unique file types.
New data sources: mobile, instant messaging and social media
Mobile devices can be difficult when it comes to e-discovery for many reasons. They contain a large variety of file types and data intermingled with a lot of private information, which may be privileged. Extracting specific information can be difficult and imaging an entire device can be costly. This is why it’s important to have policies in place to determine how mobile devices are used for business purposes.
Organizations are also relying on messaging platforms – Slack, Teams and WhatsApp are good examples – and social media to conduct business. Data can usually be requested from the source company. For example, Instagram has a data request form in its privacy and security settings, but it can be difficult to put into a review-ready format. So knowing if these platforms are a potential source of data, should litigation arise, is important.
New data sources: mobile, instant messaging and social media
Besides the file types listed here, there are a myriad of other unsupported file types which may come into play. A good example are CAD (computer-aided design) files used by an architecture or construction company. Because they are used every day by members of an organization, the fact that they may be difficult to process for review may not be considered in the event of legal action.
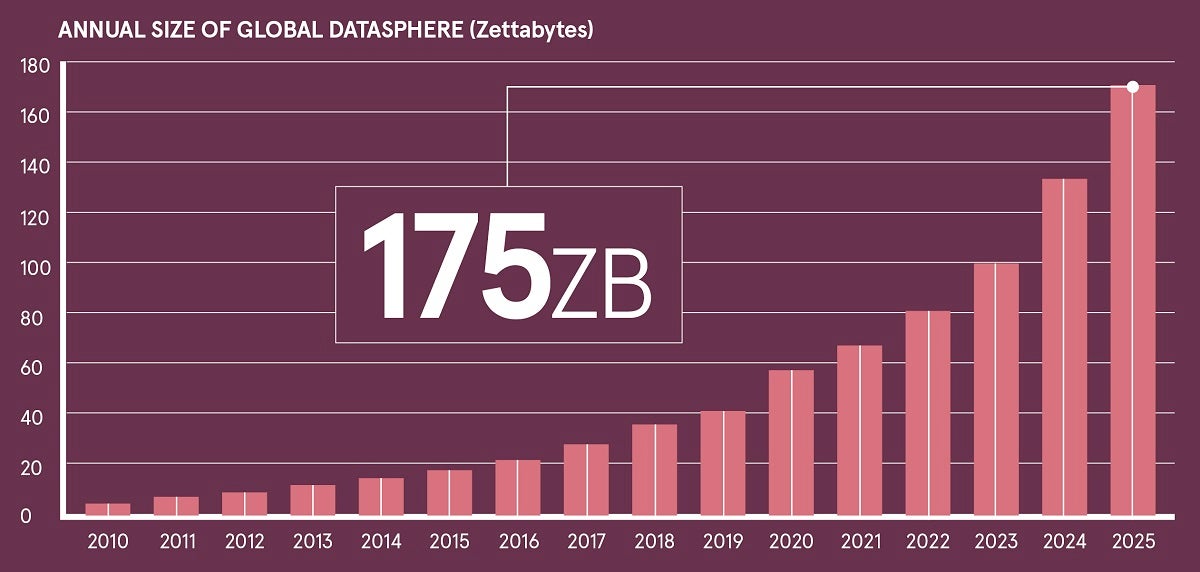
Size matters: understanding your organization’s overall dataset
Besides knowing the file types your organization may use, knowing the size of that data is also difficult to capture, especially with the exponential growth of electronic information each year. Doing a data inventory will give you an idea of how much data is created for a given amount of time, as well as how much of that data may be ROT (redundant, obsolete, trivial).
Don’t wait until litigation is imminent
It’s easy to get stuck in a “that’s the way we’ve always done it” mentality, but data-processing challenges shouldn’t get in the way of your legal team’s ability to understand the facts in a matter quickly.
To download a full pre-litigation data inventory checklist and learn more about how Ipro Tech helps corporations significantly reduce the cost and complexity of e-discovery with a hybrid approach of software, services and support, please go to www.Iprotech.info/Raconteur
